穿过幻觉荒野,大模型RAG越野赛

2025年初,大模型赛场热度不减,有拼成本优势,拼Tokens调用量的短跑赛;有比慢思考,比大模型推理能力的长跑赛。但在观看这些“经典赛事”的同时,我们还需要注意另一场正在举行中,并且对大模型行业未来至关重要的比赛——RAG越野赛。
所谓RAG,是指Retrieval-Augmented Generation检索增强生成。顾名思义,RAG是将大语言模型的生成能力与搜索引擎的信息检索能力进行结合,这已经成为目前主流大模型的标配。
之所以说RAG是一场越野赛,是因为大模型最被人质疑的问题,就是生成内容时经常会出现有明显讹误的大模型幻觉。这些幻觉就像崇山峻岭,遮挡了大模型的进化之路。
而RAG的战略价值,就在于它是克服大模型幻觉的核心方案。换言之,谁能赢得RAG越野赛,谁就能解决大模型的核心痛点,将AI带到下一个时代。
让我们进入大模型RAG的赛道,看看这场越野将把AI带向何方。
让我们先把时针调回到你第一次接触大语言模型的时候。初次尝试与大模型聊天,惊艳之外,是不是感觉好像有哪里不对?
这种不适感,很可能来自大模型的三个问题:
1.胡言乱语。对话过程中,我们经常会发现大模型说一些明显不符合常识的话,比如“林黛玉的哥哥是林冲”“鲁智深是法国文学家”之类的。这就是LLM模型的运行原理,导致其在内容生成过程中会为了生成而生成,不管信息正确与否。这也就是广受诟病的大模型幻觉。业内普遍认为,幻觉不除,大模型就始终是玩具而非工具。
2.信息落后。大模型还有一个问题,就是知识库更新较慢,从而导致如果我们问近期发生的新闻与实时热点它都无法回答。但问题在于,我们工作生活中的主要问题都具有时效性,这导致大模型的实用价值大打折扣。
3.缺乏根据。另一种情况是,大模型给出了回答,但我们无法判断这些回答的真伪和可靠性。毕竟我们知道有大模型幻觉的存在,进而会对AGIC产生疑虑。我们更希望能够让大模型像论文一样标注每条信息的来源,从而降低辨别成本。
这些问题可以被统称为“幻觉荒野”。而想要穿越这片荒野,最佳途径就是将大模型的理解、生成能力,与搜索引擎的信息检索融合在一起。
因为信息检索能够给大模型提供具有时效性的信息,并且指明每条信息的来源。在检索带来的信息库加持下,大模型也可以不再“胡言乱语”。
检索是方法,生成是目的,通过高质量的检索系统,大模型有望克服幻觉这个最大挑战。
于是,RAG技术应运而生。
在RAG赛道上,检索的优劣将很大程度上影响生成模型最终生成结果的优劣。比如说,百度在中文搜索领域的积累,带来了语料、语义理解、知识图谱等方面的积淀。这些积淀有助于提升中文RAG的质量,从而让RAG技术更快在中文大模型中落地。在搜索引擎领域,百度构建了庞大的知识库与实时数据体系,在众多需要专业检索的垂直领域进行了重点布局。
其实,把搜索领域的积累,第一时间带到大模型领域,这一点并不容易。因为我们都知道,面向人类的搜索结果并不适合大模型来阅读理解。想要实现高质量的RAG,就需要寻找能够高效支持搜索业务场景和大模型生成场景的架构解决方案。
百度早在2023年3月发布文心一言时就提出了检索增强,大模型发展到今天,检索增强也早成为业界共识。百度检索增强融合了大模型能力和搜索系统,构建了“理解-检索-生成”的协同优化技术,提升了模型技术及应用效果。通俗来看,理解阶段,基于大模型理解用户需求,对知识点进行拆解;检索阶段,面向大模型进行搜索排序优化,并将搜索返回的异构信息统一表示,送给大模型;生成阶段,综合不同来源的信息做出判断,并基于大模型逻辑推理能力,解决信息冲突等问题,从而生成准确率高、时效性好的答案。
就这样,RAG成为百度文心大模型的核心差异化技术路径。可以说,检索增强成为文心大模型的一张名片。
让我们随便问个问题,测测
如今,基本主流大模型都会提供RAG体验,比如告知用户模型调用了多少个网页,检索信息的出处在哪里等。但RAG这场越野赛依旧有着鲜明的身位差距,想要知道这个排位方法也非常简单,随便问各款大模型一个相同的问题就可以。
比如说,春节将至,逛庙会是北京春节必不可少的一部分。但北京春节庙会众多,小伙伴们肯定会想知道哪个庙会更适合自己,以及他们的营业时间是怎么样的。
于是,我把“北京春节庙会哪个更推荐?它们的营业时间是什么?”分别提问给百度文心一言、豆包、Kimi、DeepSeek等。在这里,文心一言我们使用的是付费版,文心大模型4.0 Turbo。
文心一言的答案是这样的,首先它结合检索到的信息,推荐了数十个北京的春节庙会,并且列出了每个庙会的地点、时间等信息。


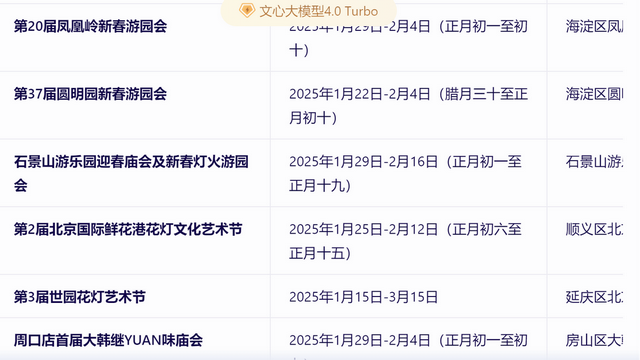
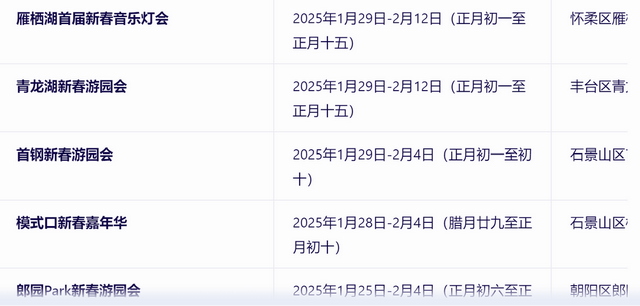
但到这里还没有结束,接下来文心一言还进行了总结。


可以看到,文心一言理解了我“最推荐”的提问,给出众多选项的同时,还主要推荐了东岳庙庙会、地坛庙会、娘娘庙庙会、石景山游乐园庙会,并且给出了相应的推荐理由,做到了在信息全面化与推荐个性化之间达成平衡。
同样的问题给到豆包,则会发现它的回答也非常不错,但内容完整度上有所欠缺。

豆包的答案,是按照每类爱好者应该去哪个庙会进行分类,总共给出了7个庙会的信息。但需要注意的是,一方面豆包的答案在庙会数量和对每个庙会特色的介绍上都不够详尽。另外豆包没有进行总结,并不符合问题中“哪个最推荐”的诉求。
同样的问题给Kimi则是另一种景象。

不知道为什么,Kimi的答案里只回答了厂甸庙会一个答案,完全没有提及其他庙会。这样确实符合“最推荐”的需求,但未免过分片面和武断,没有让用户完整了解北京春节庙会的信息。
同样的问题来问最近火热的DeepSeek R1大模型,会发现它也能进行RAG深度联网检索,并且给出了思考过程,最终给出了10个庙会的推荐信息。


唯一稍显不足的是,其最终也是只给出了几个庙会的基本情况,没有呼应“最推荐”哪个庙会的提问,并且其思考过程稍显冗长,阅读体验也有待提升。
从中不难看出,在“今年春节去哪个庙会”这样非常具有时效性与实用性的问答上,几家大模型回答得都还可以,但还是有差异的。这背后就是RAG技术能力的差异。
单看RAG能力,文心一言在检索增强,尤其是上面这类问答类需求上更显优势,另外我们也能看到,文心一言在结果呈现上调用了表格工具来结构化呈现结果。整体来说,在深度思考和工具调用上,文心一言表现不错。
不难看出,检索增强对大模型实用性和体验感有着非常重要的影响。

RAG越野赛的持续,或许将会给整个数字世界带来新的惊喜。
比如说,RAG可能是——
1.搜索引擎的新引擎。让大模型理解信息检索,也将反向带给搜索引擎与全新发展动力,用户的模糊性搜索、提问性搜索、多模态搜索将被更好满足。
2.大语言模型的新支点。大模型不仅要生成内容,更要生成可信、可靠、即时的内容,想要实现这些目标,RAG是已经得到验证的核心方向。
3.通往未来的一张船票。预训练大模型只是故事的起点,而故事的高潮则在于创造AI原生应用的无尽可能性。理解、生成、检索这些数智核心能力的相遇与融合,或许才能真正揭示出AI原生应用的底层逻辑与未来形态。
基础模型本身是需要靠应用才能显现出来价值。这个时代无数人在好奇,AI原生应用的核心载体应该是什么?
或许,理解、检索与生成的结合就是方向。
又或许,RAG越野赛的尽头就是答案。

- 湖南成立国际商会物流与供应链专业委员会 解决“出海”痛点堵点,湖南成立国际商会物流与供应链专业委员会 解决“出海”痛点堵点
- 市值攀上1.6万亿!工业富联的“新故事”和“旧标签”
- “神二十一”飞天在即!乘组地面训练精彩瞬间→,“神二十一”飞天在即!乘组地面训练精彩瞬间→
- 十年后沪指再度站上4000点 你赚钱了吗?
- 爱尔眼科可持续公益模式助力眼健康公平普惠,爱尔眼科可持续公益模式助力眼健康公平普惠
- 国家金融监督管理总局核准江朝阳招商银行股份有限公司董事
- 10月27日人民币对美元中间价报7.0881元 上调47个基点,10月27日人民币对美元中间价报7.0881元 上调47个基点
- 核聚变等新兴产业东风已至,天工国际(0826.HK)以材料创新激活新动能
- 政策显效 市场信心增强:税收数据稳步回升 经济向好态势不断稳固,政策显效 市场信心增强:税收数据稳步回升 经济向好态势不断稳固
- 内蒙古15名青少年用音乐架桥展北疆风情,内蒙古15名青少年用音乐架桥展北疆风情
- 新品解读:雷鸟鹤6 26款的“万象分区”为何是彩电市场的一记重拳
- 洽洽食品三季报解读:业绩保持平稳,新品新渠道成关键引擎,洽洽食品三季报解读:业绩保持平稳,新品新渠道成关键引擎
- 把握“924行情”科技主升浪 汇安基金近一年揽获4只“收益翻倍基”
- 《常州市优化营商环境条例》获批 以法治护航营商环境,《常州市优化营商环境条例》获批 以法治护航营商环境
- 上市公司动态 | 科大讯飞三季度净利增202%,宁德时代前三季度净利增36.20%,三一重工H股定价20.30-21.30港元
- 前三季度经济数据出炉 从关键数据看中国经济,前三季度经济数据出炉 从关键数据看中国经济